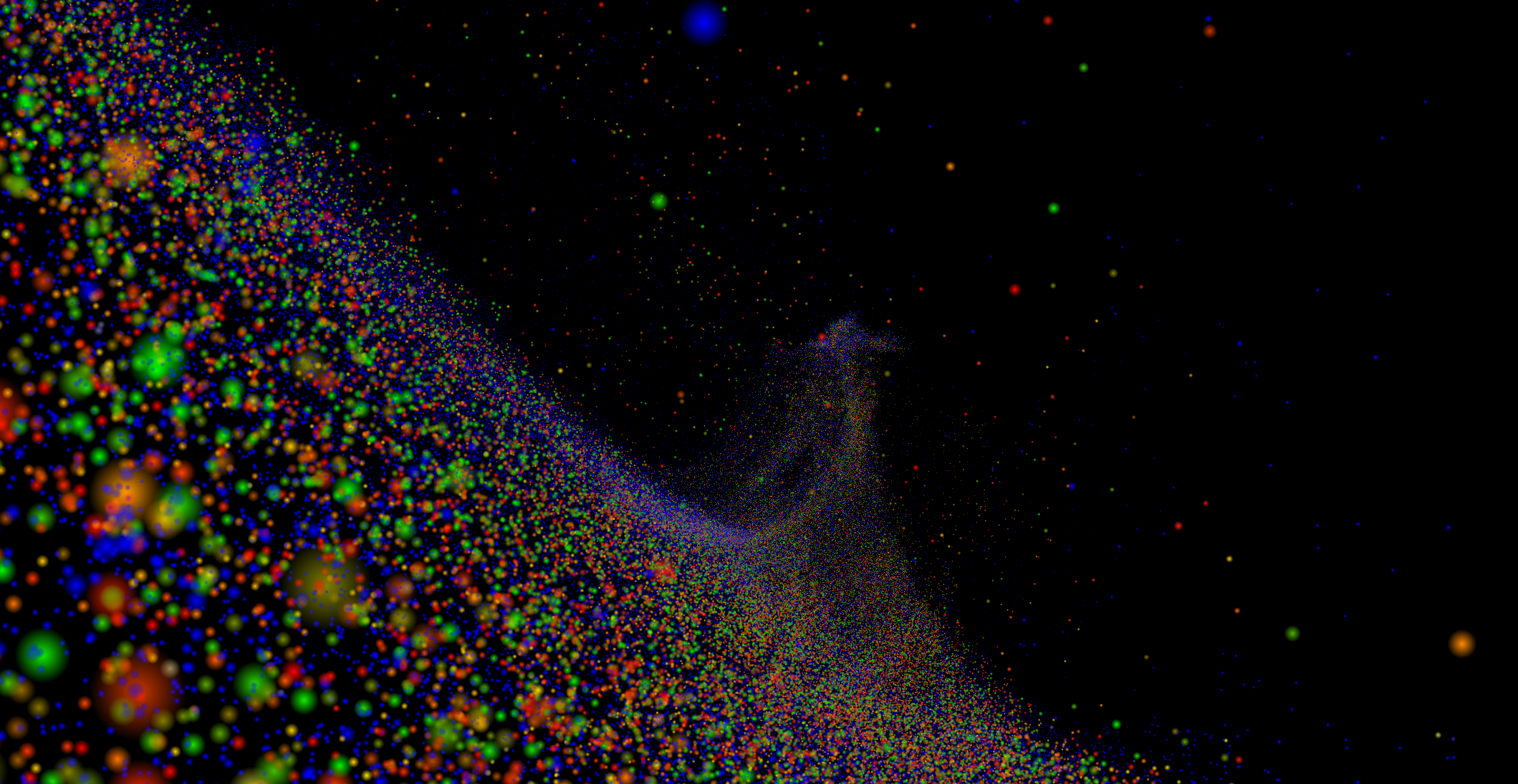
Neon is a comprehensive multiplatform graphics engine engineered from the ground up using C++20 and Vulkan. Unlike generic rendering frameworks, Neon provides a robust, type-safe API designed for scalability, capable of handling scenes with millions of instances where traditional engines falter.
It bridges the gap between low-level GPU control and high-level application logic, featuring a custom Entity-Component-System (ECS) optimized for spatial locality, a fully asynchronous asset management pipeline, and an intelligent render path that prioritizes geometry instancing.
Core Features
:: Vulkan-First Architecture
Built strictly on Vulkan to leverage modern GPU features. It abstracts the complexity of synchronization and memory barriers while keeping the performance benefits of low-level access.
:: Smart Instancing
A core rendering philosophy based on Geometry Instancing. Neon automatically manages instance memory, uploading only the smallest range of modified data to the GPU to minimize bandwidth usage.
:: Clustered Memory ECS
Implements ClusteredLinkedCollection, a custom data structure
that ensures components are contiguous in memory while allowing dynamic
expansion via linked memory blocks.
:: Runtime Shader compilation
Includes an integrated compiler stack (glslang & SPIRV-Tools) allowing developers to write, modify, and compile GLSL shaders to SPIR-V at runtime without external tools.
:: Integrated ImGUI Editor
Features a fully functional, dockable editor built using ImGUI. Includes a live scene graph, entity inspector, and real-time property modification for rapid prototyping and debugging.
:: Async Task System
A custom TaskRunner and thread pool system that offloads heavy operations (like model loading) to background threads, ensuring zero stalls on the main render thread.
The Tech Stack
Neon’s stack was selected to maximize modern C++ features and maintain low-level control over the hardware.
| Component | Technology | Reasoning |
|---|---|---|
| Language | C++20 | Utilizing Concepts, Ranges, and Smart Pointers for safety. |
| Graphics | Vulkan 1.3 | For Bindless Descriptors and Mesh Shader support. |
| Shaders | GLSL -> SPIR-V | Can be compile online or offline. |
| Math | Rush (Custom) | Written from scratch for specific SIMD optimizations. |
| Build | CMake & Vcpkg | For cross-platform dependency management. |
Technical Architecture
Neon’s architecture is defined by its modular lifecycle and strict memory management strategies.
1. Memory Management: The ClusteredLinkedCollection
Standard std::vector implementations suffer from pointer invalidation upon resizing. Neon solves this with ClusteredLinkedCollection, a hybrid structure composed of linked fixed-size memory blocks.
- Spatial Locality: Elements within a block are contiguous, maximizing CPU cache hits during iteration.
- Pointer Stability: Memory addresses remain valid throughout the object’s lifecycle, allowing safe referencing between components.
- Lifecycle Optimization: The engine uses a template-based structure,
ComponentImplementedEvents, to detect at compile-time which lifecycle methods (e.g.,onUpdate,onLateUpdate) a component overrides, avoiding unnecessary virtual calls during the loop.
2. The Rendering Pipeline
Neon is designed around Instancing. When an object requests a model,
it reserves a small memory space within the model’s instance buffer.
The engine tracks changes and, during the draw phase, uploads only the modified memory regions to the GPU.
This allows rendering scenes with 13+ million active particles with a performance up to
5x higher than equivalent OpenGL implementations.
Performance Benchmarks
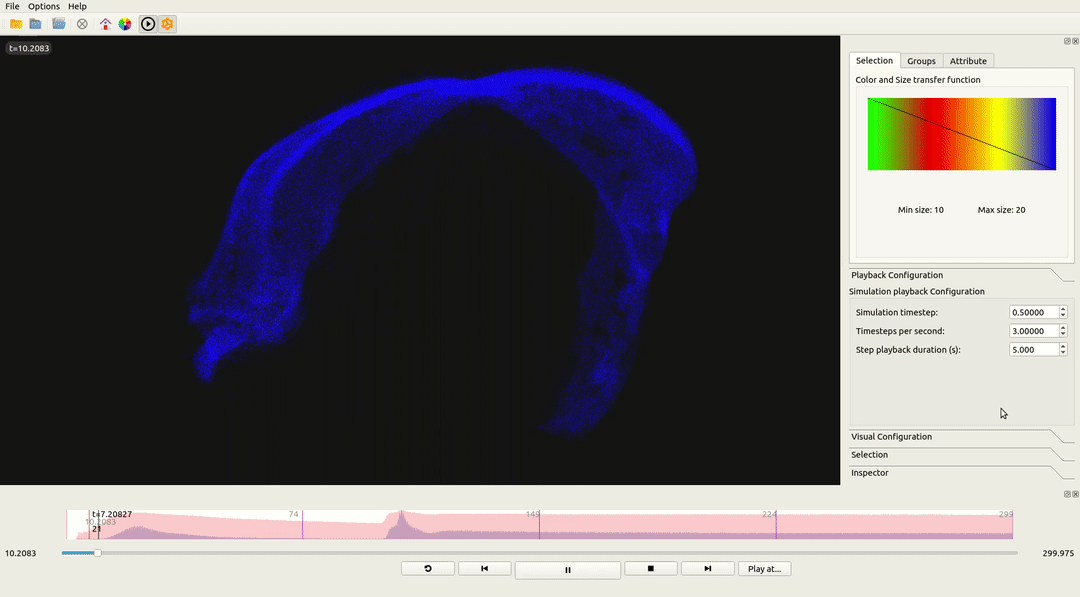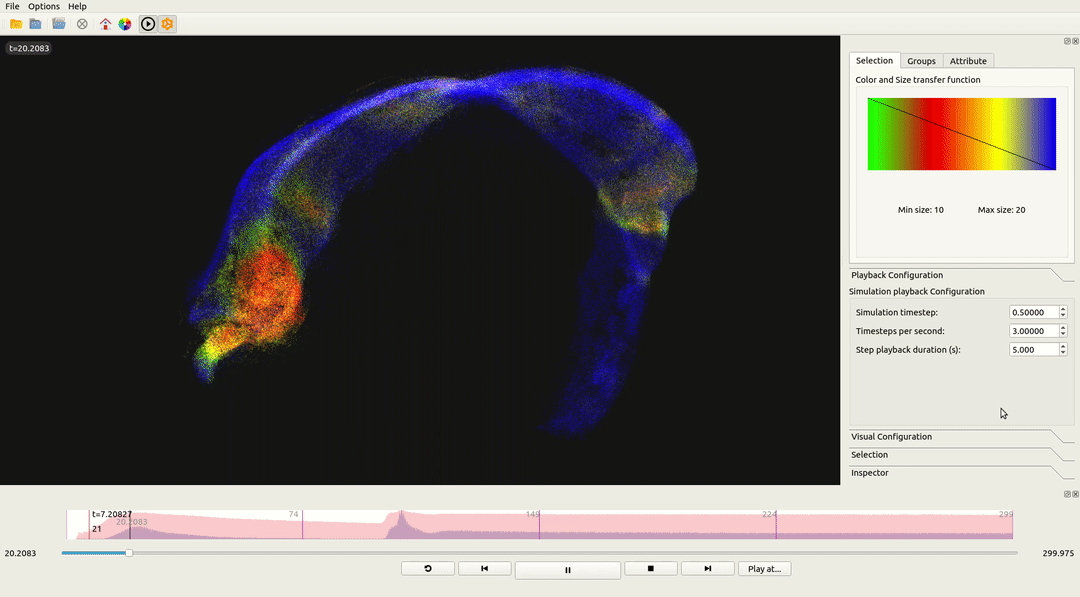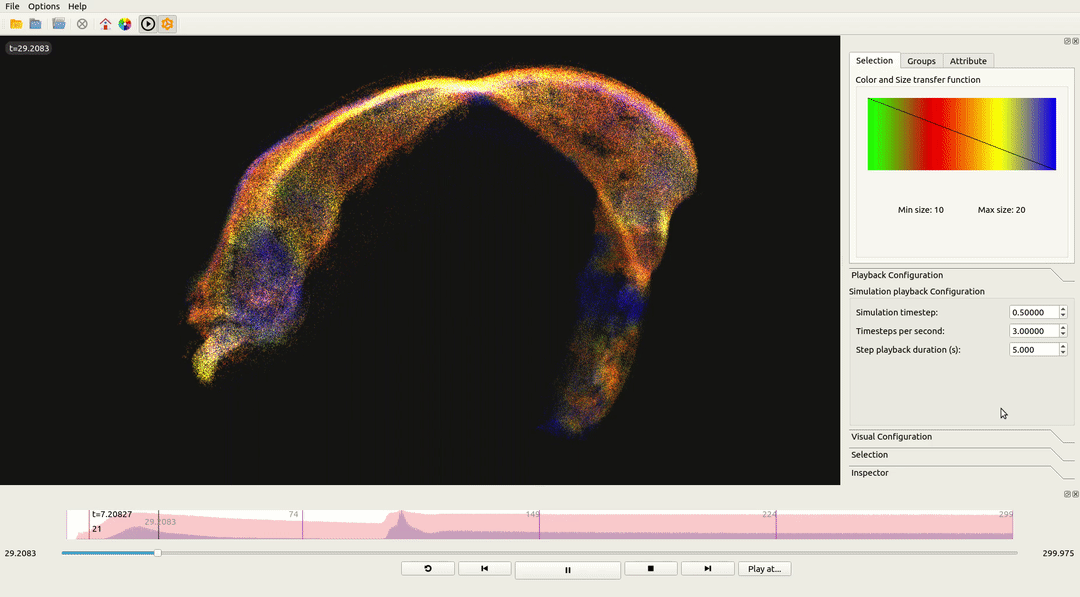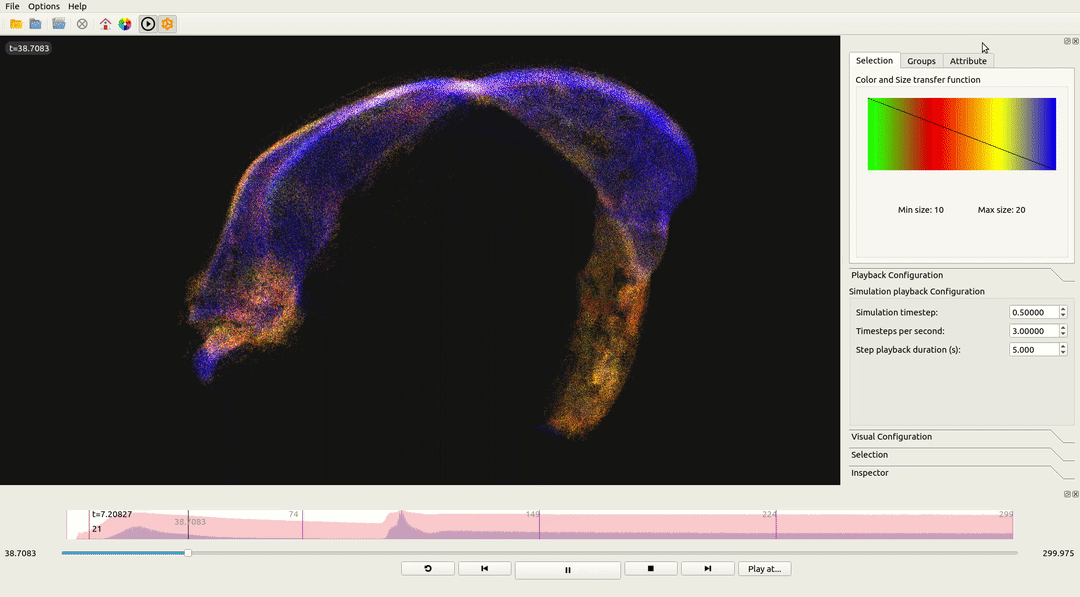
To validate the engine’s architecture, Neon was integrated into ViSimpl, a neuroscience visualization tool, replacing its legacy OpenGL engine.
| Metric | OpenGL Legacy | Neon (Vulkan) | Improvement |
|---|---|---|---|
| 13M Particles (Avg) | ~180ms | ~35ms | 5.1x Faster |
| Stability (1% Lows) | Severe spikes | Consistent | Reduced Stutter |
| CPU Overhead | High (Driver overhead) | Low (Batching) | Efficient |
Implementation Details
Neon leverages C++20 Concepts to enforce type safety without the verbosity of SFINAE. Below is an example of the user-facing API for creating logic components. Note the clean syntax and lack of boilerplate.
// RotatorComponent.h
#include <neon/structure/Component.h>
#include <rush/Rush.h>
class RotatorComponent : public neon::Component {
public:
rush::Vec3f rotationAxis = {0, 1, 0};
float speed = 1.0f;
void onUpdate(float deltaTime) override {
// Direct access to the optimized transform component (contiguous memory)
auto& transform = getGameObject()->getTransform();
// Applying rotation using custom math library
transform.rotate(rotationAxis, speed * deltaTime);
}
};
// Automatic registration for reflection and serialization systems
REGISTER_COMPONENT(RotatorComponent, "Rotator")Challenges & Solutions
Rendering Pipeline Bottlenecks
Loading high-fidelity assets (4K textures, high-poly models) typically freezes the main thread, causing noticeable frame drops.
Implementing a Virtual File System paired with a TaskRunner. Assets are mapped, loaded,
and processed in a background thread pool. A thread-safe AssetCollection
registry manages their lifetime, ensuring resources are only
uploaded to the GPU via a transfer queue when fully ready.
Memory Fragmentation
Traditional object-oriented hierarchies (pointer chasing) often lead to severe cache misses, bottlenecking the CPU during the physics and logic steps.
The ECS was designed to prioritize Data Locality. By storing active components in contiguous memory
arrays and utilizing custom allocators (minimizing new/delete calls), the engine
minimizes heap fragmentation and maximizes L1/L2 cache hits during the OnUpdate loop.
Optimization of Lifecycle Iterations
Iterating over thousands of components where many do not implement every lifecycle method (like
onLateUpdate) wastes significant CPU cycles on empty virtual calls.
Implementing ComponentImplementedEvents, a template metaprogramming structure that detects overridden
methods at compile time. Neon only iterates over the collections of components that actually implement the
specific lifecycle stage.
Efficient Data Transfer
Uploading the entire instance buffer to the GPU every frame creates a massive bandwidth bottleneck, especially in scenes with millions of static or semi-static objects.
Implementing a Dirty Range Tracker. The engine calculates the smallest contiguous memory range that encompasses all modified instances and only uploads that specific slice to the GPU, making the operation transparent to the developer.